Geminiとは:Googleの最新AIモデルの概要
Googleの最新のマルチモーダルAIモデル「Gemini」が話題になっています。テキスト、画像、音声、動画、コードなど、多様なデータタイプを統合して処理するマルチモーダル能力。
chatgptを凌駕するとも言われる本モデルの詳細に迫ります。
Geminiの基本的な特徴と能力
GeminiはGoogleが開発した最新のマルチモーダルAIモデルです。テキスト、画像、音声、動画、コードなど、多様なデータタイプを理解し組み合わせて操作できる能力を持っています。
従来のAIモデルは単一のデータタイプを扱うことが一般的でしたが、Geminiはこれらを克服し、複数のデータタイプを統合して処理することが可能です。これにより、AIの用途が大幅に拡大し、より複雑なタスクに対応できるようになりました。
Geminiは何ができるの? マルチモーダル能力とは
Geminiは何ができるの?
Geminiは、Googleが開発した最先端のマルチモーダルAIモデルで、テキスト、画像、音声、動画、コードなど、多様なデータタイプを理解し組み合わせて操作する能力を持っています。
従来のAIモデルは主に単一のデータタイプを扱うことが一般的でしたが、Geminiはこれらを克服し、複数のデータタイプを統合して処理することが可能です。これにより、AIの応用範囲が大幅に拡大し、より複雑なタスクに対応できるようになりました。
Geminiの特徴は以下の通りです:
- 洗練された推論能力:Geminiは、大量のデータの中で判別が難しい情報を抜き取るなど、複雑なテキストや視覚情報を理解することができます。
- マルチモーダル性:Geminiは、テキスト、画像、音声などを同時に理解できます。これにより、数学や物理学などの複雑な内容でも細かいニュアンスを読み取り、難しい問題や質問にも対応することができます。
- コーディング能力:Geminiは、Python、Java、C++、Goなどのプログラミング言語でコードの説明や理解、生成することができます。
Geminiの応用例としては、以下のようなものがあります:
テキストと画像を組み合わせて映画やアニメのストーリーボードを作成する。
音声とテキストを組み合わせて会話型AIの回答を生成する。
画像とコードを組み合わせて新しいソフトウェアのデザインを行う。
Geminiのマルチモーダル技術の解説
Geminiのマルチモーダル性能は、その最大の特徴です。このモデルは、異なるタイプのデータを理解し、それらを統合して問題を解決する能力を持っています。例えば、画像認識やビデオキャプション生成など、複数のモードを跨いだタスクで高いパフォーマンスを発揮しています。これにより、Geminiはより複雑で現実世界に近い問題に対応できるようになっています。Geminiの応用範囲は広く、多様な分野での利用が期待されています。例えば、科学文献の解析、競技プログラミング、オーディオ信号のエンドツーエンド処理、数学や物理の推論説明など、専門的なタスクにも対応可能です。
GeminiとChatGPTの比較:特徴と違い

GeminiとChatGPTの機能比較
- Geminiはテキスト、画像、音声、動画など複数のデータ形式を統合して処理する能力を持っています。
- ChatGPTは主にテキストベースの対話を主な機能としています。
- Geminiは特に映像をリアルタイムで認識し、対話する能力において他の生成AIを凌駕しています。
- Geminiは画像認識と画像生成を組み合わせ、画像・映像・テキストを同時に認識する能力を持っています。
Gemini Ultraは各値GPT-4を上回る数値
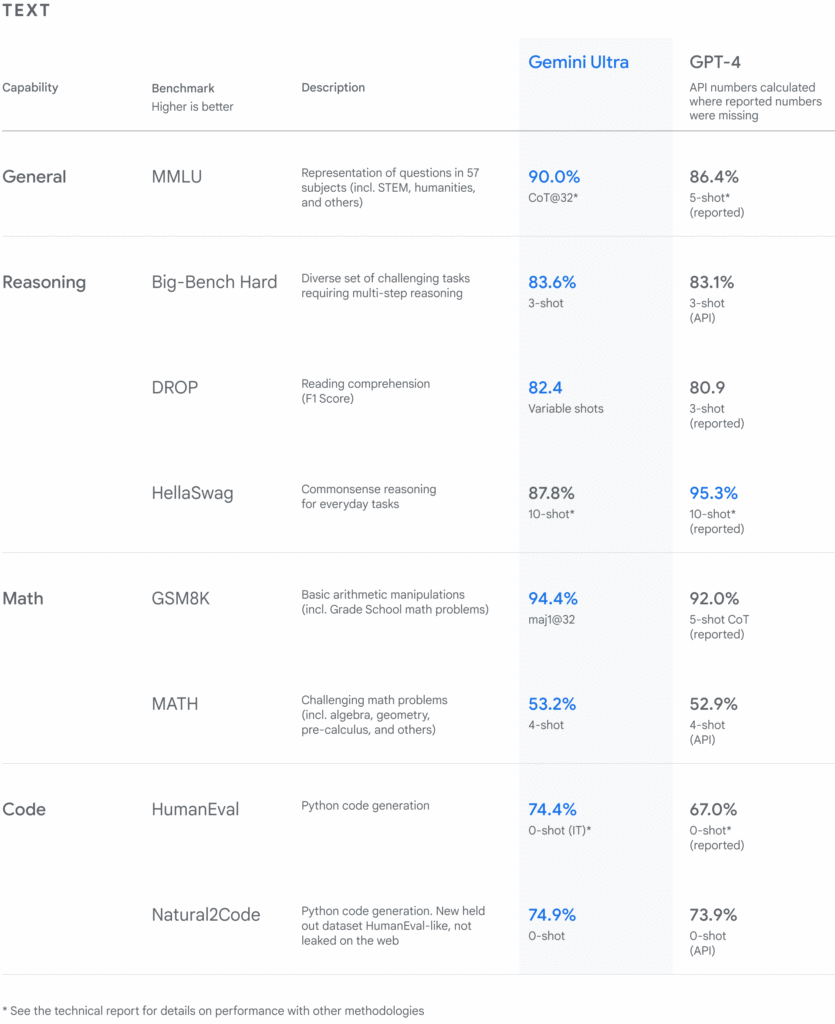
どのような場面でGeminiがChatGPTに優れるか
Geminiはマルチモーダルな情報処理能力においてChatGPTを上回ります。例えば、Geminiは映像をリアルタイムで認識し、対話することができ、画像や映像を元にした質問に対しても的確な回答を提供できます。これは、科学研究や医療分野でのデータ分析、ビジネスにおける複雑なデータの解釈など、マルチモーダルな情報が重要な場面で特に有効です。また、Geminiは画像や映像を元にコードを生成する能力も持っており、開発者やエンジニアにとって有用なツールとなり得ます。
Geminiの使い方

h3: Geminiのセットアップと基本操作
アクセス方法:
現在、GeminiはPixel 8スマートフォン(Gemini Nano)とBardチャットボット(Gemini Pro)で利用できます。
Geminiの利用可能なプラットフォーム:
Pixel 8スマートフォンでは「Gemini Nano」が利用可能。
Bardチャットボットでは「Gemini Pro」が利用可能。
Googleの将来の計画:
Googleは、検索、広告、Chromeなどの他のサービスにGeminiを統合する計画を持っている。
Geminiの利用方法:
GoogleのAIアシスタントBardを通じてGeminiのセットアップが行われる。
Googleアカウントの言語設定を英語に変更する必要がある。
Googleアカウントの設定ページから「個人情報」の「ウェブ向け全般設定」で言語を英語に設定。
BardにアクセスするとGeminiが利用可能になる。
Gemini Pro APIのアクセス方法:
Google AI StudioやGoogle Cloud Vertex AIを通じてアクセス可能。
Android開発者はAndroid 14のAICoreでGemini Nanoを使用できる。
Gemini Ultraのリリース予定:
安全性と信頼性のチェックを経た後、開発者と企業向けにリリースされる予定。
Geminiの応用例と実践的な活用方法
Geminiは、そのマルチモーダルな能力を活かして、多岐にわたる応用が可能です。例えば、画像に書かれたテキスト情報の読み取り、スライド資料の解説、手書きメモの整理、論文の検索・読解作業の自動化などが挙げられます。
Geminiのビジネスへの応用可能性
Geminiは、そのマルチモーダルな能力により、ビジネス分野での応用が大いに期待されています。特に、データ分析、市場調査、顧客サービスの自動化など、情報処理が重要な業務においてその価値を発揮します。Geminiは、テキスト、画像、音声、動画などの多様なデータ形式を統合して分析することができ、これにより、より深い洞察や正確な意思決定を支援します。例えば、マーケティング分野では、消費者の行動や傾向を多角的に分析し、より効果的な戦略を立案することが可能です。また、顧客サポートでは、顧客の問い合わせに対して、より迅速かつ正確な回答を提供することができます。
- 画像に書かれたテキスト情報の読み取り。
- スライド資料の解説。
- 手書きメモの整理。
- 論文の検索・読解作業の自動化。
- Webページの内容をURLから要約する機能。
- 科学者、法律家、財務関係者など、データセットに依存する多くの分野での応用が期待されている。
- テキスト、画像、音声などのマルチモーダル情報を認識し理解するために訓練されている。
- 複雑な話題に対する質問に答える能力を持っている。
Geminiの応用範囲と将来性

Geminiの将来展望とAI技術への影響
Geminiは、AI技術の将来に大きな影響を与えると考えられています。その最大の特徴は、マルチモーダルなデータ処理能力にあります。これにより、Geminiは従来のAIモデルでは困難だった複雑なタスクを解決することが可能になります。例えば、科学研究や医療分野では、大量のデータから新たな知見を発見することが期待されます。また、教育分野では、よりパーソナライズされた学習体験の提供が可能になるでしょう。Geminiの進化は、AIが人間の知識や理解を補完し、さらには超える可能性を示しており、これにより、AIの応用範囲が大幅に広がり、より実用的で革新的なソリューションの開発が可能になると考えられます。
Geminiの開発背景とGoogleの目的
Geminiの開発は、GoogleのAI技術の進化における重要な一歩です。Googleは、AIが日常生活を改善し、イノベーションと経済発展を促進する機会を提供すると信じています。Geminiは、GoogleのAIファースト戦略の一環として開発され、人間のように複雑な情報を統合して理解し、問題を解決する能力を持つことを目指しています。このモデルは、Googleが企業として取り組んできた科学およびエンジニアリングの取り組みの中でも最も大きなものの一つであり、AI技術の新たな地平を切り開くものと期待されています。